
















Ruj, Blazer ve Cesaret / Bir "Biz" Hikâyesi
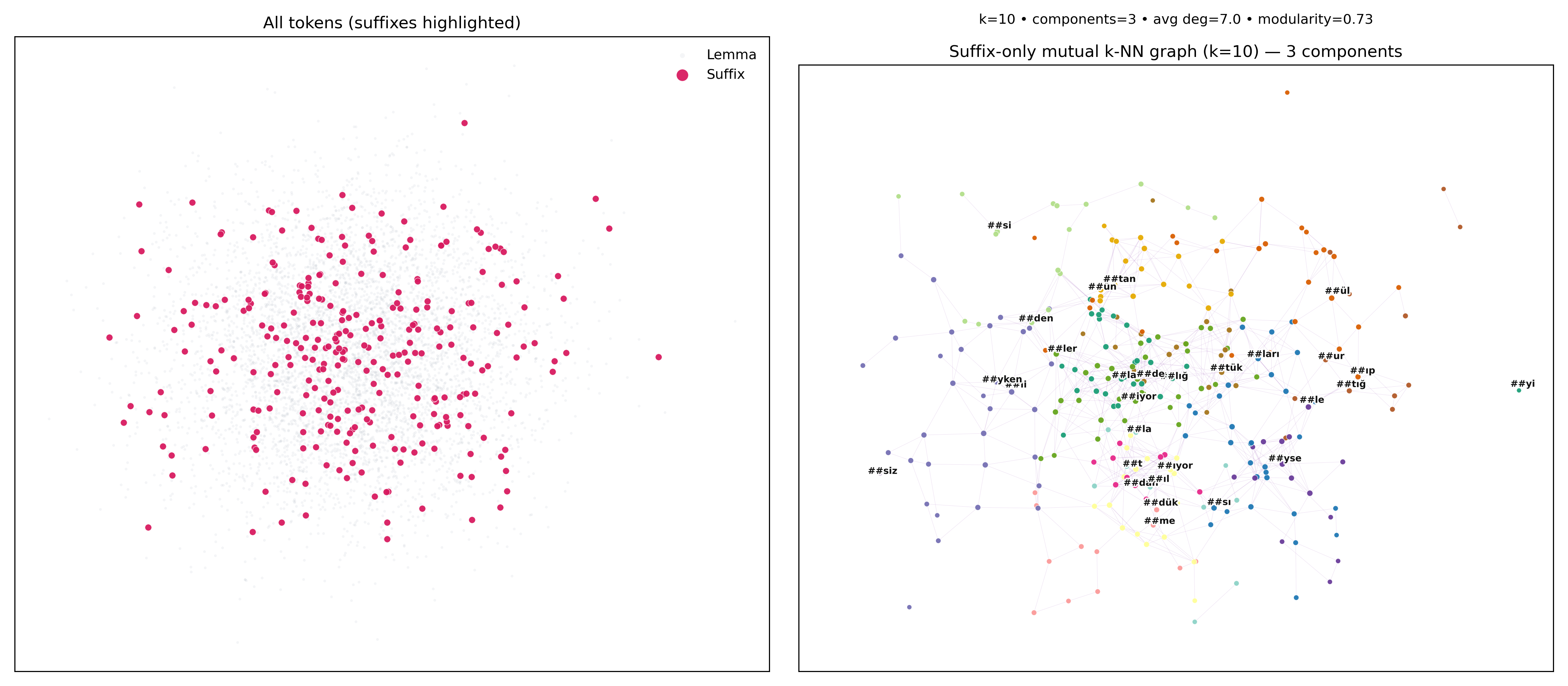
Bu yazıda 8 Mart için küçük bir “biz dili” manifestosuna başlıyoruz: Türkiye’de kadınların kadınlara yazdığı güzellik, stil ve yaşam yazılarında dayanışma nasıl kuruluyor? SüslüTrendler derleminden yola çıkarak; kombin, makyaj, iyi...
Read More