Turkish morphology is fascinating and even more fascinating when you process it with spaCy Turkish models. In this article, quantify and characterize Turkish morphological info in news using spaCy Turkish by building practical morphological-only utilities: normalization, case/possessive/verb-morph analytics and suffix-aware search. Zero NER, zero parsing, maximum suffix joy.
Turkish morphology is like LEGO for linguists: click-click-click and suddenly one word is carrying tense, person, case, possessive, mood, polarity, and whether your neighbor merely heard the news or actually saw it. Most NLP write-ups jump straight to NER and dependency parsing. Not today. We’re going full minimalist: just morphology. No NER, no syntax trees—just suffix magic, a few normalization tricks, and plots that actually tell you something.
What’s the point?
- See how much structure you can squeeze out of raw Turkish news using only spaCy’s morphological features.
- Build tiny, useful tools: case-aware search, possessive and pronoun summaries, verb-morph timelines, and a softening audit (hello p/ç/t/k → b/c/d/ğ).
- Keep it practical: a handful of functions, a few plots, zero dependency parsing anxiety.
Why morphology-only? Because Turkish gives you VIP access to meaning via suffixes. Case tells you who’s going where, possessives hint at who owns what, tense/mood/evidentiality sketch the timeline and “how sure are we?” stance. You can do real analytics without touching NER. Seriously.
Setup (quick and painless)
Python 3.9+
spaCy 3.7+
tr_core_news_trf, the official spaCy Turkish model
pandas and matplotlib for a bit of visualization
Havadis, your ultimate Turkish news corpus
First we install the requirements. The second line is gonna install the spaCy model tr_core_news_trf from the official spaCy Turkish models Hugging Face repo:
pip install -U spacy pandas matplotlib
pip install https://huggingface.co/turkish-nlp-suite/tr_core_news_trf/resolve/main/tr_core_news_trf-1.0-py3-none-any.whl
pip install datasets
After making the pips, now we can go ahead and download our dataset Havadis from the official Havadis HF repo:
from datasets import load_dataset
dataset = load_dataset("turkish-nlp-suite/Havadis", split="train")
texts = dataset["text"] # the dataset only has a single field, text
Each instance of the Havadis includes a news article. An instance looks like:
1 Karat Kaç Gramdır? Bir Karat Kaç Gram?
Değerli madenleri ölçmek için kullanılan bir ölçü birimi olarak karat ifade edilmektedir. Özellikle elmas başta olmak üzere pek çok değerli madeni ölçmek amaçlı önemli bir yere sahiptir. Bu doğrultuda karat ölçüm birimi aynı zamanda gram üzerinden de dönüşüm şansı vermektedir.
Bu dönüşüm üzerinden bakıldığında ise bir karat 0,2 grama denk gelir. Böylece değerli taş madenlerin kütleleri hesabı yapılmak suretiyle buna uygun şekilde fiyatlandırması çıkarılır. Özellikle de güncel piyasa konusunda önemli yere sahiptir....
Next we load the spacy model into out Python shell:
nlp = spacy.load("tr_core_news_trf")
Before the dataset mining, we’ll warm up to the morphological tags of the package. .morph feature holds the morphological tags of a token just like:
doc = nlp("Ekip İstanbul'dan Ankara'ya hareket etti; açıklama dün yayımlandı mı?")
for tok in doc:
print(f"{tok.text:<15} POS={tok.pos_:<6} LEMMA={tok.lemma_:<12} MORPH={tok.morph}")
Ekip POS=NOUN LEMMA=ekip MORPH=Case=Nom|Number=Sing|Person=3
İstanbul'dan POS=PROPN LEMMA=İstanbul MORPH=Case=Abl|Number=Sing|Person=3
Ankara'ya POS=PROPN LEMMA=Ankara MORPH=Case=Dat|Number=Sing|Person=3
hareket POS=NOUN LEMMA=hareket MORPH=Case=Nom|Number=Sing|Person=3
etti POS=VERB LEMMA=et MORPH=Aspect=Perf|Evident=Fh|Number=Sing|Person=3|Polarity=Pos|Tense=Past
; POS=PUNCT LEMMA=; MORPH=
açıklama POS=VERB LEMMA=açıkla MORPH=Case=Nom|Number=Sing|Person=3|Polarity=Pos
dün POS=NOUN LEMMA=dün MORPH=Case=Nom|Number=Sing|Person=3
yayımlandı POS=VERB LEMMA=yayımla MORPH=Aspect=Perf|Evident=Fh|Number=Sing|Person=3|Polarity=Pos|Tense=Past|Voice=Pass
mı POS=AUX LEMMA=mi MORPH=Aspect=Imp|Number=Sing|Person=3|Tense=Pres
? POS=PUNCT LEMMA=? MORPH=
When we look at the noun “Ekip”, we see it’s in nominative case and singular in number. The proper noun “Ankara’ya” is in dative case and again singular. The verb “etti” is in past tense, the action is completed hence it’s past perfect, it’s not in evidential form (-mIş), polarity is positive and is in 3rd person. The second verb “yayımlandı” is in passive voice.
If you’re curious about the origins of the tags (namely BOUN treebank), please visit the previous post about the package making.
This corpus is cleaned and normalized for some characters includign apostrophe, so we won’t do much of text cleaning. We are gonna collect the morphological tags and simply count them. We start with question clitics -mI :
def is_question_particle(tok):
return tok.pos_ == "AUX" and tok.lower_ in {"mi","mı","mu","mü"}
Next we can count case markers (ismin halleri -, -A, -dA, -dAn, -I, -In) and possesive marker (-I, Duygu’nun evi):
def get_case(tok):
v = tok.morph.get("Case")
return v[0] if v else None
def get_possessive(tok):
v = tok.morph.get("Person[psor]")
return v[0] if v else None
Here, Person[psor] marks the possesion, can be 1,2,3 person as in “evim”, “evin”, “evi” and can be plural for “evimiz”, “eviniz”, “evleri”. Coming to the verbs, number of features is high including tense, aspect, mood, polarity..:
def verb_morph_bundle(tok):
m = tok.morph
def one(feat):
vals = m.get(feat)
return vals[0] if vals else None
return {
"Tense": one("Tense"),
"Aspect": one("Aspect"),
"Mood": one("Mood"),
"Polarity": one("Polarity"),
"Evident": one("Evident"),
"Person": one("Person"),
"Number": one("Number"),
}
Now we’re going to count number of apostrophes, hence estimate the number of proper nouns:
def split_apostrophe_form(text):
APOS ="'"
if APOS in text:
base, suff = text.split(APOS, 1)
return base, suff
return text, None
Final count is a fancy and shiny Turkish linguistic rule, consonant softening:
def softened(lemma, form):
if not lemma or not form:
return False
pairs = {"p":"b","ç":"c","t":"d","k":"ğ"}
l = lemma[-1].lower()
if l not in pairs or len(form) < len(lemma):
return False
# Compare stem minus last char; last char should soften
return (form[:len(lemma)-1].lower() == lemma[:-1].lower()
and form[len(lemma)-1].lower() == pairs[l])
We’re ready to make the corpus statistics:
from collections import Counter
import matplotlib
def collect_stats(lines):
stats = {
"noun_case": Counter(),
"pron_case": Counter(),
"noun_possessive": Counter(),
"verb_tense": Counter(),
"verb_mood": Counter(),
"verb_evident": Counter(),
"verb_polarity": Counter(),
"q_particles": 0,
"acc_total": 0,
"acc_soft": 0,
"verb_total": 0,
"noun_total": 0,
"pron_total": 0
}
for doc in nlp.pipe(lines, batch_size=64):
for tok in doc:
if tok.pos_ == "NOUN":
stats["noun_total"] += 1
c = get_case(tok)
if c: stats["noun_case"][c] += 1
p = get_possessive(tok)
if p: stats["noun_possessive"][p] += 1
if c == "Acc":
stats["acc_total"] += 1
if softened(tok.lemma_, tok.text):
stats["acc_soft"] += 1
elif tok.pos_ == "PRON":
stats["pron_total"] += 1
c = get_case(tok)
if c: stats["pron_case"][c] += 1
if tok.pos_ in {"VERB","AUX"}:
stats["verb_total"] += 1
b = verb_morph_bundle(tok)
if b["Tense"]: stats["verb_tense"][b["Tense"]] += 1
if b["Mood"]: stats["verb_mood"][b["Mood"]] += 1
if b["Evident"]: stats["verb_evident"][b["Evident"]] += 1
if b["Polarity"]: stats["verb_polarity"][b["Polarity"]] += 1
if is_question_particle(tok):
stats["q_particles"] += 1
return stats
def plot_counter(title, counter, topn):
items = counter.most_common(topn) if topn else list(counter.items())
if not items:
print(f"{title}: no data.")
return
labels, values = zip(*items)
plt.figure(figsize=(6,3))
plt.bar(labels, values, color="#2266aa")
plt.title(title)
plt.xticks(rotation=25)
plt.tight_layout()
plt.show()
then run our shiny code on the Havadis data. All dataset is couple of GBs, hence we’ll process the first 100 documents from the dataset. Remember each document is a newspaper article and contains enough number of words for counting purposes.
stats = collect_stats(texts)
print("\n— Stats —")
print("Case on NOUNs:", stats["noun_case"])
print("Case on PRONs:", stats["pron_case"])
print("Possessive on NOUNs:", stats["noun_possessive"])
print("Verb Tense:", stats["verb_tense"])
print("Verb Mood:", stats["verb_mood"])
print("Verb Evident:", stats["verb_evident"])
print("Verb Polarity:", stats["verb_polarity"])
if stats["acc_total"]:
rate = stats["acc_soft"]/stats["acc_total"]*100
print(f"Accusative softening rate: {stats['acc_soft']}/{stats['acc_total']} = {rate:.1f}%")
print("Question particles (mi/mı/mu/mü):", stats["q_particles"])
plot_counter("Case distribution on NOUNs", stats["noun_case"])
plot_counter("Possessive distribution on NOUNs", stats["noun_possessive"])
plot_counter("Verb Tense distribution", stats["verb_tense"])
plot_counter("Verb Evidentiality distribution", stats["verb_evident"])
plot_counter("Verb Polarity distribution", stats["verb_polarity"])
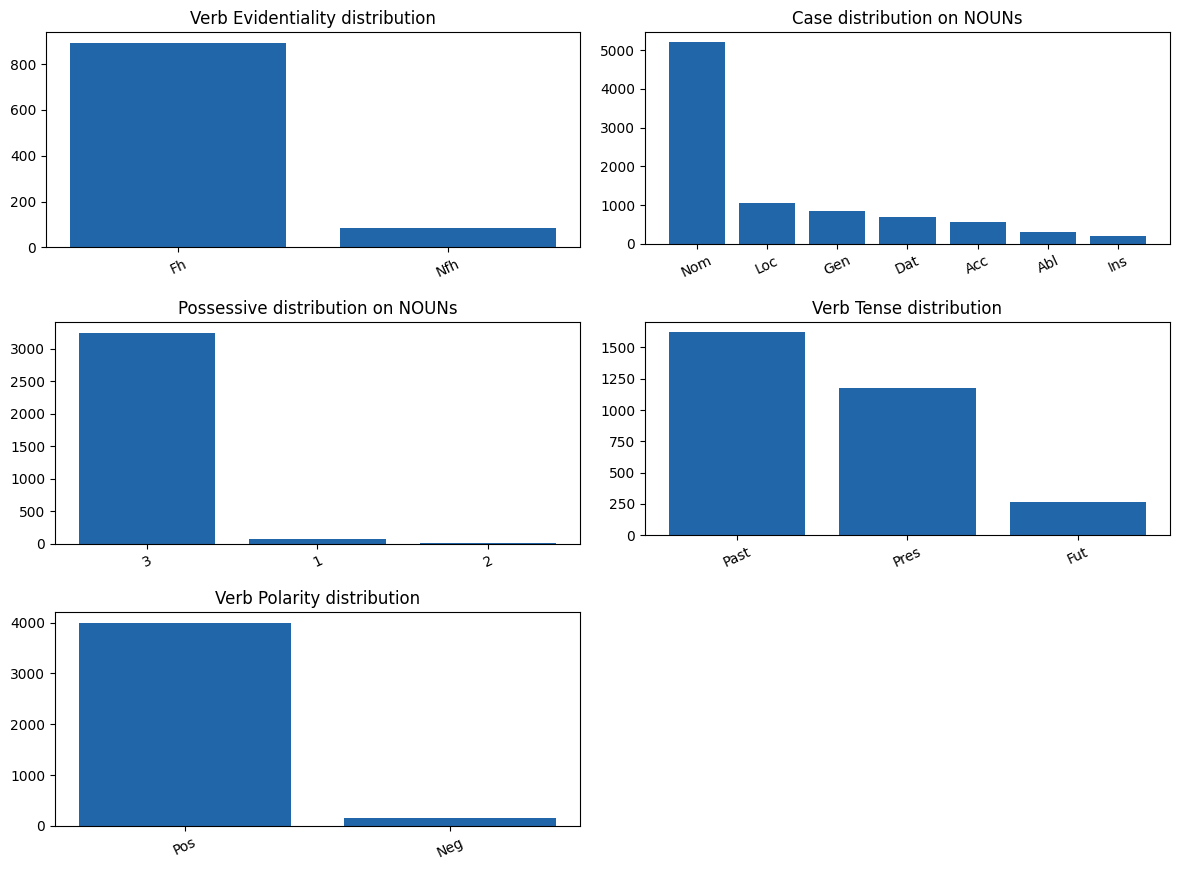
Here are the results:
— Stats —
Case on NOUNs: Counter({'Nom': 5201, 'Loc': 1052, 'Gen': 839, 'Dat': 706, 'Acc': 555, 'Abl': 307, 'Ins': 208})
Case on PRONs: Counter({'Nom': 79, 'Dat': 28, 'Gen': 28, 'Acc': 9, 'Loc': 9, 'Ins': 7, 'Abl': 7})
Possessive on NOUNs: Counter({'3': 3247, '1': 74, '2': 6})
Verb Tense: Counter({'Past': 1620, 'Pres': 1178, 'Fut': 266})
Verb Mood: Counter({'Imp': 169, 'Cnd': 86, 'Pot': 76, 'Ind': 37, 'Nec': 14, 'Des': 4, 'Opt': 3, 'Gen': 2})
Verb Evident: Counter({'Fh': 894, 'Nfh': 85})
Verb Polarity: Counter({'Pos': 4002, 'Neg': 153})
Accusative softening rate: 29/555 = 5.2%
Question particles (mi/mı/mu/mü): 7
First the verbs, most of the verbs are in past tense. In news the current events are narrated hence it’s totally expected past tense to occur most.Coming to the evidentiality, the result is also expected as news are usually in non-evident form i.e. “gitti” vs “gitmis”. Most of the verbs are positive as well, negation isn’t used much. Coming to the mood, almost all moods are used, imperative, conditional (-sA), potential mood (-AbIl) and more. Coming to the nouns and pronouns, nominative case is the winner. For the possession, 3rd person marker is the winner as first or second person possession doesn’t really suit news language (imagine evim, evimiz, eviniz, evin in the newspaper articles!!). Consonant softening composes 5.2% of all suffixation and there were 7 questions entences in the first 100 documents. All statistics are exhibited in the above figure, please look up :blush:
We made a small morphological parsing practice, more of spaCy Turkish models do not stop and jump onto the next article for syntax in fairy tales. Joy of processing Turkish always exist in our blog pages, you just need to keep going and read!